
In this post, I will review the main recommendation systems at a very high level, comparing different techniques, and finally, check the evaluation metrics for these kinds of algorithms.
Recommendation systems aim to suggest the likely items that users will find interesting based on their interests and product characteristics. That is why these systems trust past behavioral data.

These systems use data analysis to discover patterns in datasets aiming to improve the users’ engagement and satisfaction. Their main objective is to leverage the long-tail items to the users with very specific interests.
There are plenty of models for recommendation systems, at following, I will present you the most relevant:
Popularity model
This model should be seen as a baseline. It is based on the “Wisdom of the crowds“. It recommends the most popular items.
In the next chart, there are the most commonly used models for recommendation systems:

Association Rules
This algorithm makes use of casual relationships between items. It attempts to point out how a series of items will define another series of items. There is another vital factor: confidence, to measure how applicable a rule is.

For example, 
The way this algorithm works is making a square matrix of all single-item relationships and their associated confidence values between all n items within the dataset. Then, we treat the user as a vector in n-dimensional space. If you multiply the matrix by the vector, you get what is referred to as a recommendation vector.
Content-based Filtering
It refers to the content or features of the products you like. So, the idea in content-based filtering is to tag products using certain keywords, understand what the user likes, look up those keywords in the database and suggest different products with the same attributes.
It recommends on a feature-level basis. It has to analyze the items and a single user’s profile for the advise. Thus, it produces more reliable results with fewer users.

It is essential to have a measurement of similarity, as a way to find any correlation (It is a statistical measure that indicates the extent to which two or more variables fluctuates together) between users based on items ratings. There are several correlation measurements:
Collaborative Filtering
This includes finding similarities between users and items to make assumptions for missing rating values and deducing new recommendations. It uses users’ behavior data to discover their activities and preferences. Then, the similarities with other users are calculated.
It gives recommendations based on other unknown. users who have the same taste as a given user.

It has a cold start. It does not give any recommendation on new users since no new information is available.
Memory-based models
It uses user rating data to compute the similarity between users or items. There are two approaches to this kind of models:
- User-based: Previous user results (interactions) to compute user similarities. Similar users who have similar ratings for similar items are found and then target user’s ratings for the item which target user has never interacted is predicted.

- Item-based: Items similarities based on what the users have interacted with. It finds similar items to items which target user already rated or interacted. These methods are more stable witch changes and rely on the items which less tend to change the users.
Model-based algorithms
It is widely used when the time to make the recommendation is vital in real-time and on large datasets. It involves building a model in which we extract some information from the dataset.
At following, there are some examples of models commonly used for building recommendation systems.
- Matrix Factorization (good at scalability and sparsity)
- Neural Networks
- Bayesian Networks
- Clustering Networks
- Singular Value Decomposition (SVD)
- Probabilistic Latent Sensitive Analysis
- Dimensionality reduction
- Decision trees
- Rule-based models
- Latent factor models
| Memory-based models | Model-based algorithms | Association Rules | |
|---|---|---|---|
| Advantages | – Good quality of predictions – Simple algorithms to implement – Easy to update the database | – High scalability – Faster models – Avoid overfitting | – Fast – Good results – Works well with sparse data sets |
| Disavantages | – It is very slow – Can easily be overfitted – Cold start | – Inflexibility – Less quality of predictions | – Susceptible to bias on the data – Cannot predict ratings, only order preferences. |
Evaluation
Depending on the model nature of your recommender system, there are some techniques to evaluate its performance:
Cross-validation: When you are dealing with a model-based algorithm, we can make use of the scikit learn cross-validation library. To predict yet-unseen data, the initial dataset is split into a training and testing set, and then, tested in the last set of data. Even as a test set still is held out for final evaluation, the validation set is no longer needed when doing cross-validation. In the basic approach, called k-fold, the training set is split into k smaller sets and the resulting model is validated on the remaining part of the data. The performance measure is then the average of the values computed in the loop.
A/B Testing: this kind of testing evaluates the impact of a new technology by running it in a real production environment and testing tis performance on a subset of the users of the platform. It is a well-known practice to run a preliminary offline evaluation on historical data. Offline performance can be measured using estimators know as counterfactual or off-policy estimators.
RMSE: It is used evaluate accuracy of a filtering technique by comparing the predicted ratings directly with the actual user rating. Mean Absolute Error (MAE), Root Mean Square Error (RMSE) and Correlation are usually used as statistical accuracy metrics. MAE is the most popular and commonly used; it is a measure of deviation of recommendation from user’s actual value. MAE and RMSE are computed as follows:

Precision@k and Recall@k: These are the go-to metrics used for recommendation systems. Let us begin with understanding what precision and recall mean for recommendation systems:



Precision and recall don’t care about ordering. We use precision and recall at cutoff k. Consider that we make N recommendations and consider only the first element, then only the first two, then only the first three, etc… these subsets can be indexed by k.
Ranking metrics
Top-N accuracy metrics: Evaluates the accuracy of the top recommendations provided to a user comparing to the items that the user has actually interacted in the test set.
NDCG@N: Normalized Discounted Cumulative Gain. Let’s say we have some items recommended, each item has a relevance score, usually a non-negative number. That’s gain. For items we don’t have user feedback for we usually set the gain to zero.
Now we add up those scores; that’s cumulative gain. We would prefer to see the most relevant items at the top of the list, therefore before summing the scores we divide each by a growing number (usually a logarithm of the item position) – that’s discounting – and get a DCG.
AP@N: Average precision. If we have to recommend N items and there are m relevant items in the full space of items, it is defined as:


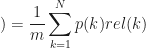


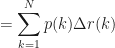
where 


References
- http://www.cs.carleton.edu/cs_comps/0607/recommend/recommender/modelbased.html
- http://www.cs.carleton.edu/cs_comps/0607/recommend/recommender/association.html
- http://www.cs.carleton.edu/cs_comps/0607/recommend/recommender/memorybased.html
- https://medium.com/@kyasar.mail/recommender-systems-memory-based-collaborative-filtering-methods-b5d58ca8383
- https://medium.com/towards-artificial-intelligence/content-based-recommender-system-4db1b3de03e7
- https://towardsdatascience.com/evaluating-a-real-life-recommender-system-error-based-and-ranking-based-84708e3285b
- http://fastml.com/evaluating-recommender-systems/
- http://fastml.com/what-you-wanted-to-know-about-mean-average-precision/
- https://towardsdatascience.com/recommendation-systems-models-and-evaluation-84944a84fb8e
- https://www.groundai.com/project/offline-ab-testing-for-recommender-systems/1
- https://scikit-learn.org/stable/modules/cross_validation.html

